
이번에는 VTK의 Pipeline Execution에 구조를 분석하고자 합니다.
시작하기에 앞서 VTK에서 visualization 에서 처리하는 데이터 모델 들에 대한 간단한 용어 정리가 필요합니다.
1. 용어 정리
Proecss Object : Process 객체는 입력데이터에 대해 출력 데이터를 생성하는 객체를 말하며, 입출력 구조에 따라 Source, Filter, Mapper object 로 나뉩니다.
- Source Object : 입력데이터 없이 출력 데이터를 만들도록 처리하는 객체
- Filter Object: 한개 이상의 입력데이터를 기반으로 한개 이상의 출력데이터를 만들도록 처리하는 객체
- Sink (Mapper) Object: 출력 데이터는 없이 한개 이상의 입력데이터만을 이용하여 처리하는 객체. Visualization pipeline을 종료 함.

2. Pipeline 실행방식
VTK 의 Pipleline은 demand-driven 방식으로 데이터처리를 수행 합니다.
풀어 말하면, 데이터가 변경되는 시점에 업데이트가 이루어지는 event-driven 방식이 아니라, 모든 데이터 처리를 완료 하고 명령요청을 한 시점에 한꺼번에 업데이트를 하는 방식입니다.
Pipeline을 실행하는데 가장 중요한 역할을 하는 것이 vtkAlgorithm과 vtkExecutive 클래스입니다.
vtkAlgorithm은 모든 Process object(Source, Filter, Mapper) 클래스들의 base 클래스이며, vtkExecutive 객체를 멤버변수로 갖습니다.
vtkAlgorithm 은 information 과 data object 처리를 수행하고, vtkExecutive 는 vtkAlgorithm이 언제 수행할 지 무슨 information 과 data object를 사용할지에 대한 정보를 관리하는 클래스입니다.
vtkAlgorithm과 vtkExecutive 간의 요청 데이터는 key-value map기반의 vtkInformation 객체를 사용합니다.

Pipeline은 마치 레고와 같이 chain 방식으로 각 Process object를 Input Port와 Output Port를 이용해 연결합니다. 연결된 Port를 통해서 information 정보를 상호간의 전달하여 요청과 업데이트를 수행합니다.
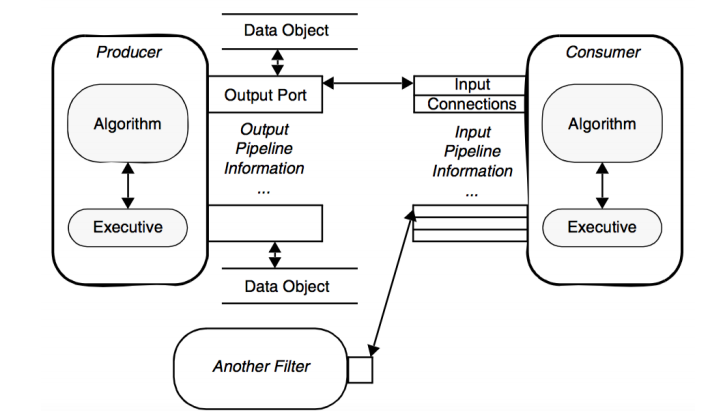
위의 표현된 그림을 코드로는 더욱 쉽게 구현할 수 있습니다.
vtkNew<vtkSphereSource> sphereSource;
sphereSource->Update();
vtkNew<vtkGeometryFilter> sphFilter;
sphFilter->SetInputConnection(sphereSource->GetOutputPort());
vtkNew<vtkPolyDataMapper> sphereMapper;
sphereMapper->SetInputConnection(sphFilter->GetOutputPort());
vtkNew<vtkActor> sphereActor;
sphereActor->SetMapper(sphereMapper);3. Information Objects
VTK의 Pipeline 이 작동할 때 사용되는 Information 은 몇가지로 구분 됩니다.
- Pipeline Information
Executive 객체가 관리하며 Input / Output 데이터에 대한 포인터 값을 갖고 있고, 필터를 수행하거나 출력 데이터를 생성할 떄 필요한 정보를 갖습니다.
아래의 예는 Output object data 에 대한 Pipeline information 입니다.
- Port Information
Algorithm 객체에서 관리하는 information 데이터이며 Algorithm 을 수행하는데 필요한 Port의 갯수와 데이터 타입 정보 등을 갖습니다.
아래의 예처럼 vtkImageResample의 경우 InputPort 에 vtkImageData 데이터를 1개를 필요로 합니다.
- Request Information
Algorithm 이 수행할 요청 사항들을 갖고 있으며 ProcessRequest() 에서 이를 처리하도록 합니다.
4. Pipeline Workflow
Pipeline 동작방식은 Process obejct 가 연결되어 있는 하단에서 위로 올라가는 요청을 UpStream Request (Update)라고 하며, 반대로 위에서 아래로 내려가는 요청을 DownStream Request (Request Dat)라고 합니다.
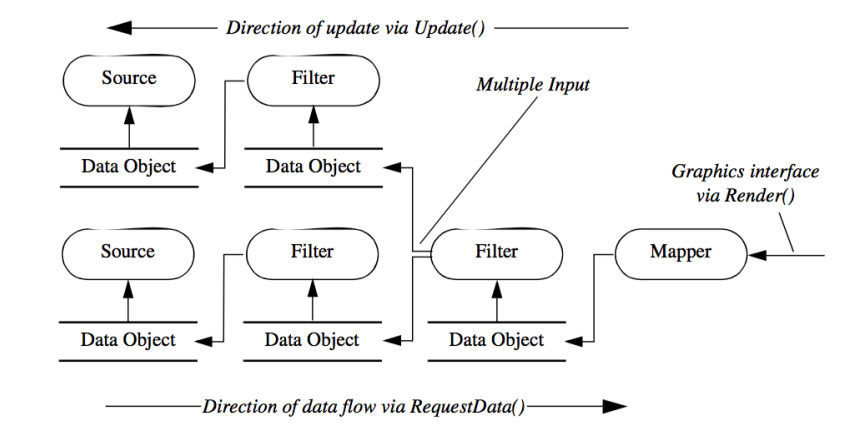
사용자가 Render 나 Write와 같은 명령을 하면 Mapper에서부터 Source 단계까지 upstream으로 update 요청이 순차적으로 전달됩니다. 전달된 update는 최상단의 object 에서부터 downstream 방향으로 request data 명령을 수행하면서 pipeline 작업을 수행하게 됩니다.
Request 정보는 Executive 를 통해 UpStream / DownStream으로 전달되며, 필요에 따라 Executive에서 Algorithm에 ProcessRequest 요청을 보냅니다.

Executive는 요청할 정보를 UpStream으로 전달하는데 Forwarding을 수행하기 전에 Algorithm에 요청하는 것을 ALGORITHM_BEFORE_FOWARD, Fowarding 이후에 하는 것을 ALGORITHM_AFTER_FOWARD 로 정의합니다.

전체적인 Update와 RequestData에 대한 동작의 흐름을 아래와 같이 나타낼 수 있습니다.
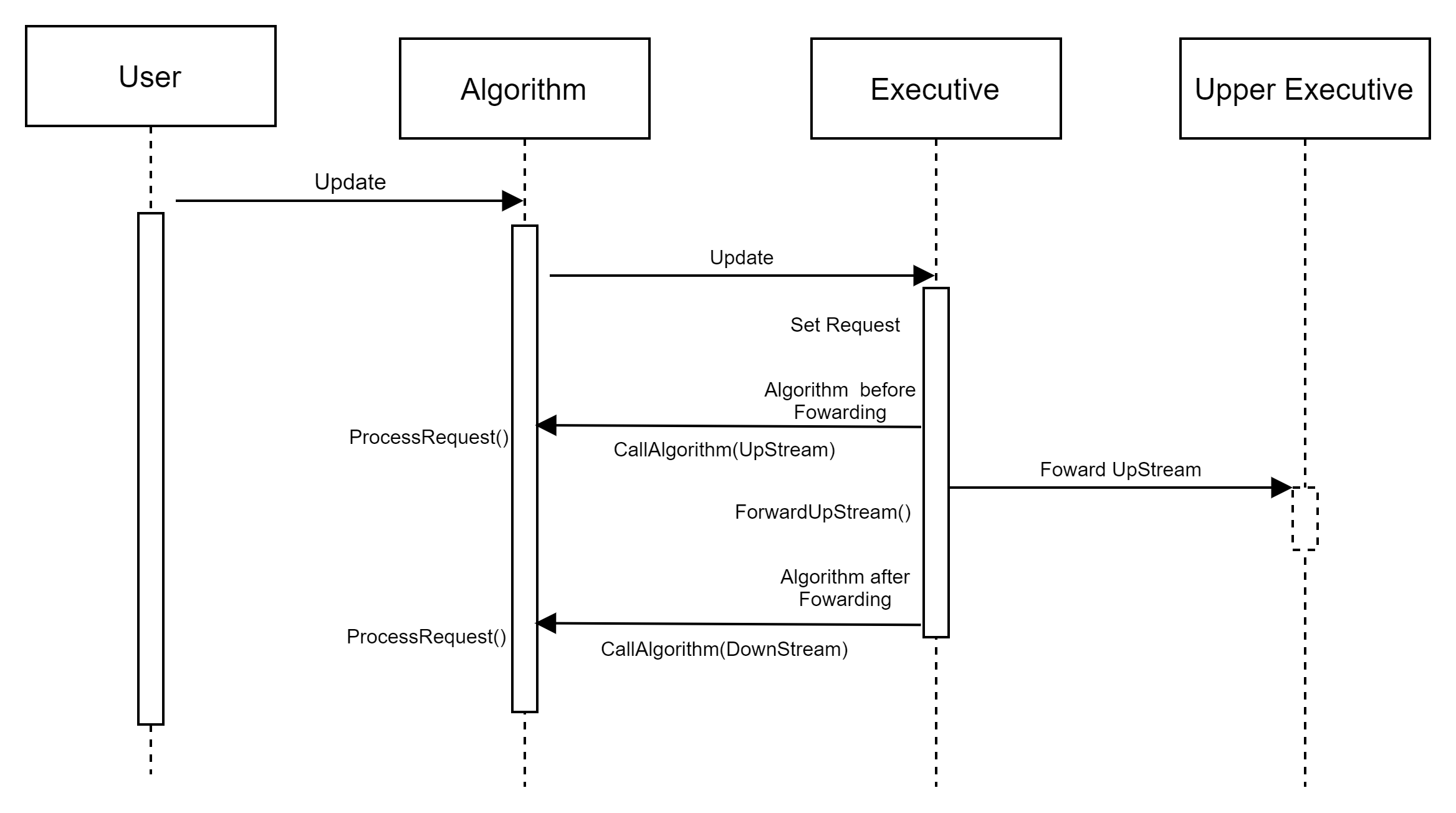
Alogirhtm의 ProcessRequest에서 수행할 동작에 대한 요청을 설정하기 위해 Executive::Update에서 Request의 종류에 따라 아래와 같이 설정을 하고 Executive::ProcessRequest 를 call 합니다.
참고로 Request의 항목들은 Executive 하위 클래스에서 목적에 따라 정의가 되어 있습니다. 좀더 자세한 내용은 다음 장에서 설명하겠습니다.
아래는 vtkDemandDrivenPipeline의 output 데이터를 생성하도록 요청하는 REQUEST_DATA_OBJECT 입니다.

이렇게 VTK의 Pipeline 동작은 Executive 와 Algorithm의 간의 Update와 Request 에 의해 수행됩니다.
실제로 Executive와 Algorithm은 수많은 자식 클래스에 의해서 구현되고 있기에 정리가 불가능합니다.
다만, 그중에서 Executive 의 대표적인 Request 정의를 알아보도록 하겠습니다.
5. Executive
Executive 는 아래와 같은 클래스들이 구현되어 있습니다.

vtkDemandDrivenPipeline
Pipeline의 Demand-driven 방식의 명령을 수행하면서 기본적으로 필요한 Request을 명령을 갖고 있습니다.
- REQUEST_DATA_OBJECT : 위에서 설명한대로 Output에 필요한 데이터 객체 생성을 요청합니다
- REQUEST_INFORMATION : Data object의 정보를 요청합니다. vtkImageData의 경우 space, origin 과 같은 정보를 얻을 수 있습니다.
- REQUEST_DATA : Output 데이터 객체의 정보를 변경 / 추가 하도록 합니다.

vtkStreamingDemandDrivenPipeline
vtkDemandDrivenPipiline에 Streaming 기능을 추가한 클래스입니다. 처리할 데이터를 subset으로 분할하여 pipeline을 수행하고 최종적으로 데이터를 합쳐서 output data를 만들 수 있도록 합니다.
- REQUEST_INFORMATION : output data에 저장이 가능한 데이터의 크기에 관한 정보를 요청합니다.
- REQUEST_UPDATE_EXTENT : 지정된 영역에 output 을 업데이트 하도록 요청합니다. (Alg. before forward)
- REQUEST_UPDATE_EXTNT_INFORMATION : 지정된 영역에 대해서만 데이터가 생성되도록 합니다.(Alg. after forward)
- REQUEST_DATA : Algorithm 에 지정된 영역을 분할해서 여러차례로 작동하여 output data를 생성하도록 합니다.

vtkCompositeDataPipeline
vtkStreamingDemandDrivenPipeline을 상속한 클래스로 multiple dataset을 구성하는 데이터에 대해 작업을 수행할 수 있도록 합니다.

6. Wrap-up
VTK 라는게 규모적으로 크기도 할 뿐더러 국내 자료가 별로 없어 접근하기가 쉽지는 않은 것 같습니다.
그렇다보니 공부하는데 어려움은 있겠으나 VTK의 뼈대가 되는 중요한 개념인 것 같아 꼭 알아두면 좋을 것 같습니다.
정리한 내용들은 모두 제 스스로 공부한 내용을 토대로 만든 것이라서 오류가 있을 수 있으며 설명한 개념이 VTK에서 말하는 내용과는 다르게 표현되어 있을 수 있습니다.
참고하시길 바라며 잘못된 개념이나 내용이 있으면 알려주시면 업데이트 하겠습니다.